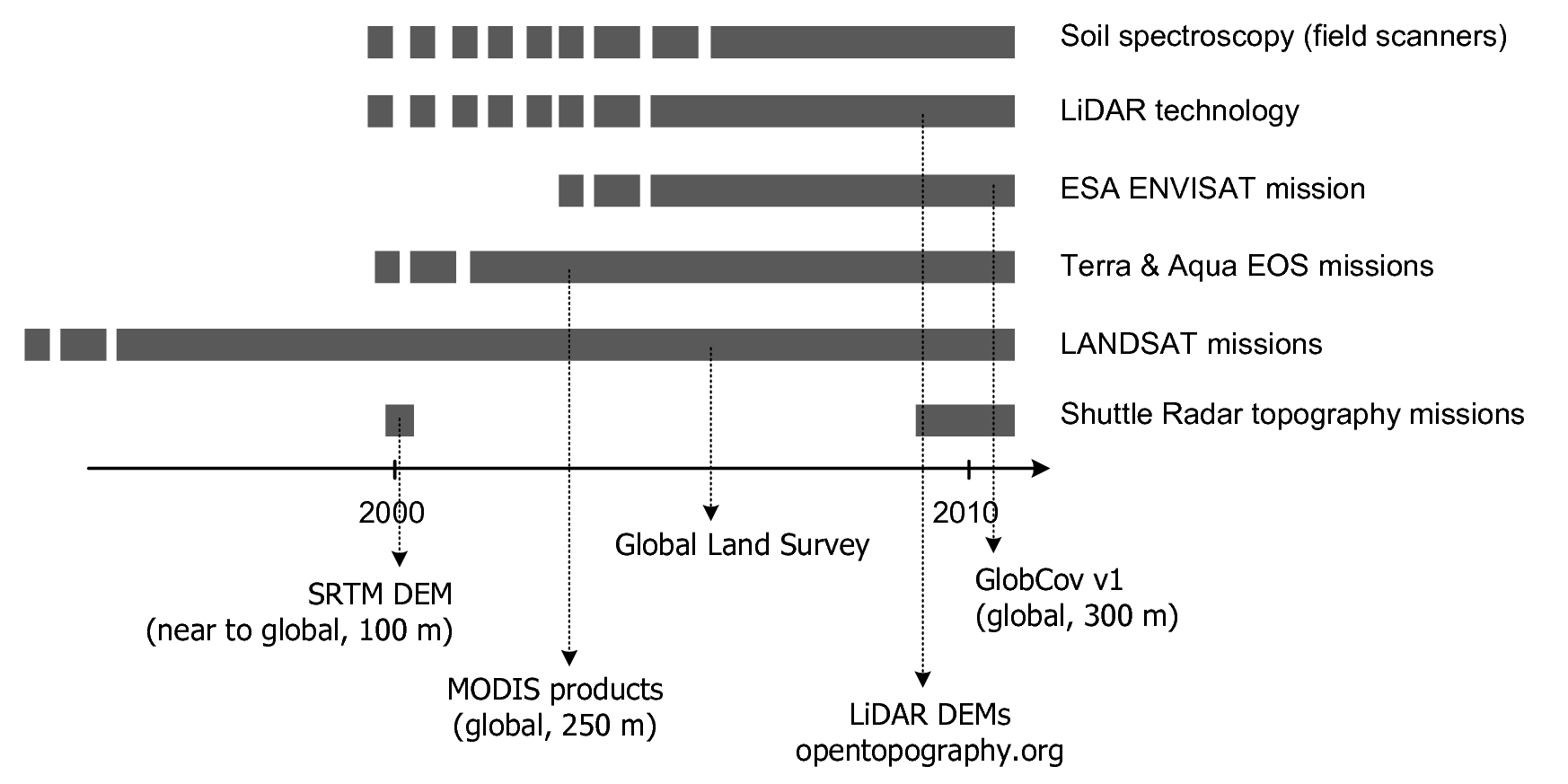
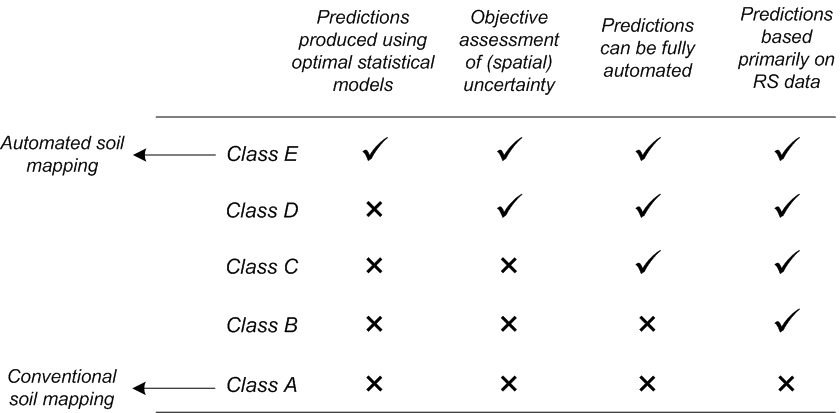
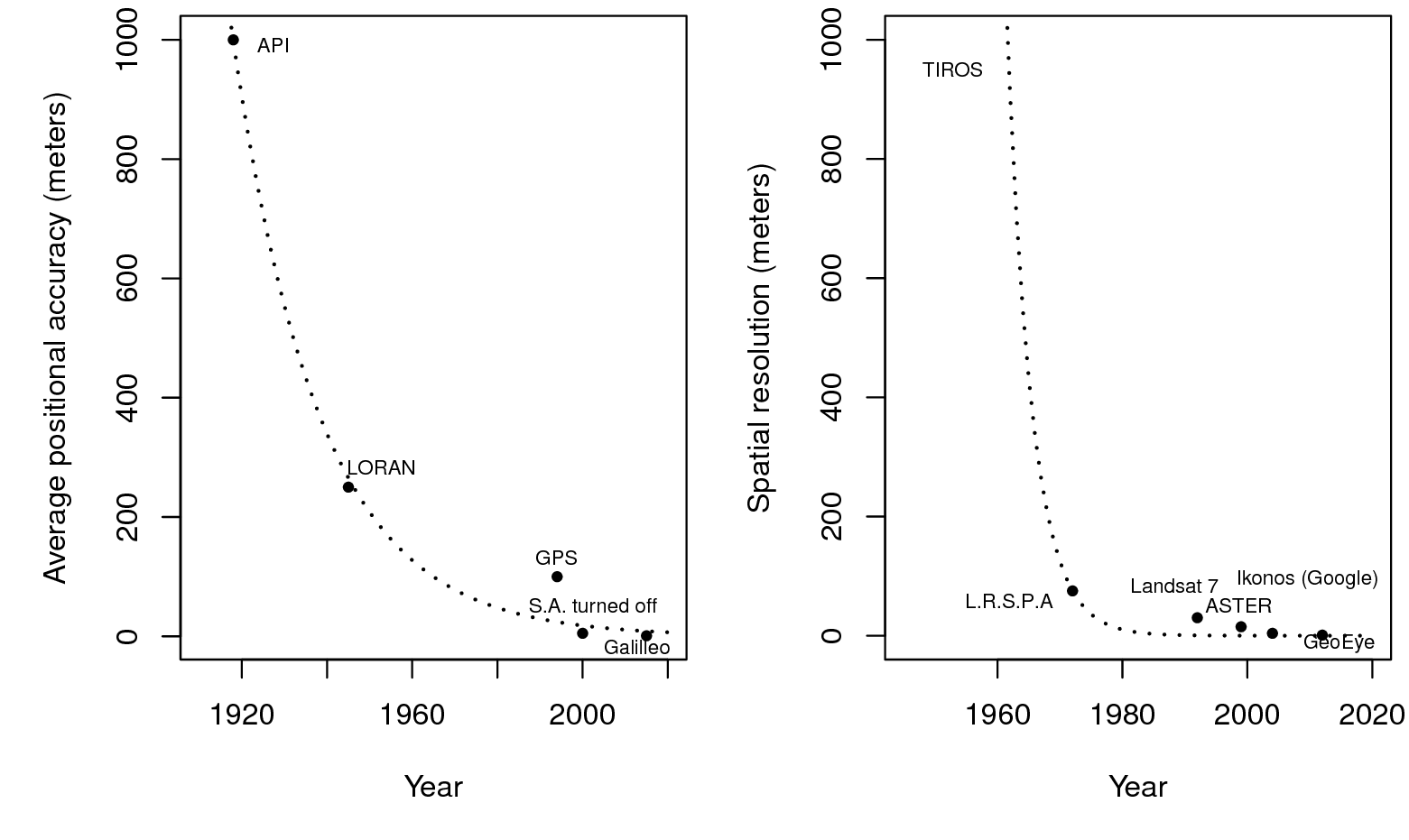
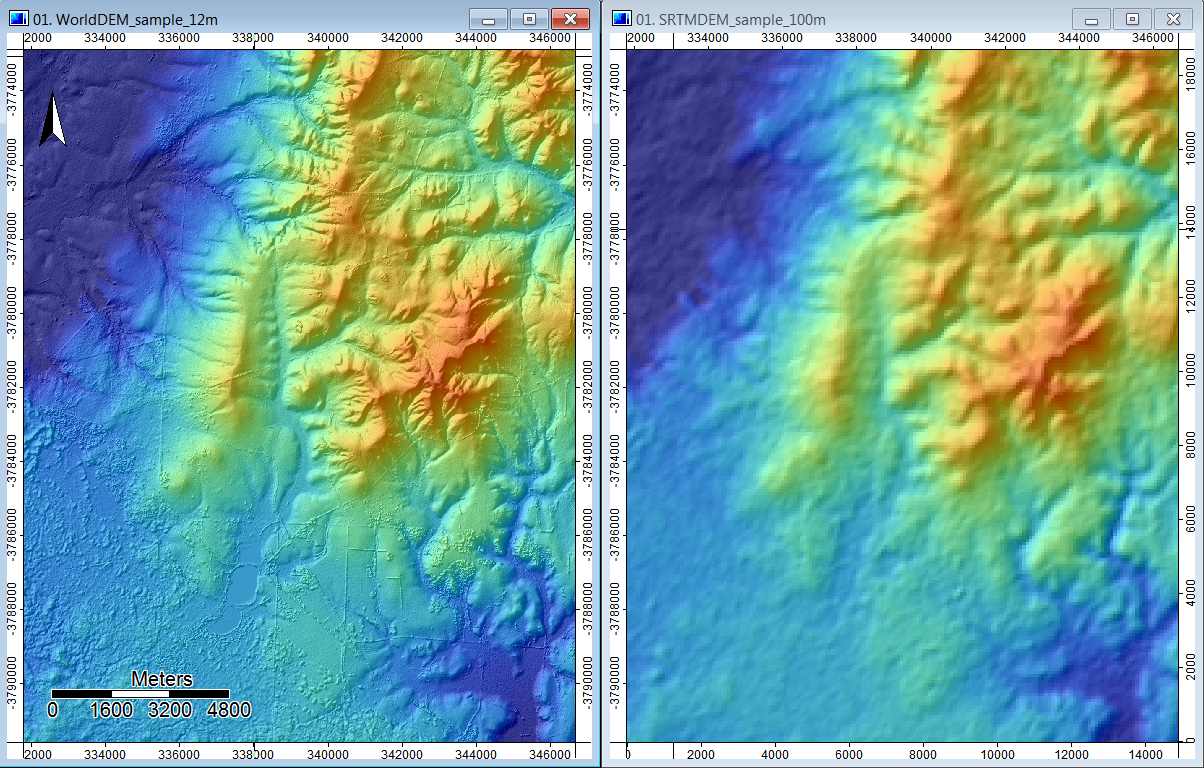
Chesworth, W. 2008. Encyclopedia of soil science. Encyclopedia of Earth Sciences Series. Springer.
Richter, Daniel D., and Daniel Markewitz. 1995. “How Deep Is Soil?” BioScience 45 (9). University of California Press on behalf of the American Institute of Biological Sciences:600–609. http://www.jstor.org/stable/1312764.
Soil survey Division staff. 1993. Soil Survey Manual. Vol. Handbook 18. Washington: United States Department of Agriculture.
Frossard, E., W.E.H. Blum, B.P. Warkentin, and Geological Society of London. 2006. Function of soils for human societies and the environment. Special Publication — Geological Society of London. Geological Society.
Wysocki, D., P.J. Schoeneberger, and H.E. LaGarry. 2005. “Soil Surveys: A Window to the Subsurface.” Geoderma 126:167–80.
de Gruijter, J. J., D. J. J. Walvoort, and P. F. M. van Gaans. 1997. “Continuous Soil Maps — a Fuzzy Set Approach to Bridge the Gap Between Aggregation Levels of Process and Distribution Models.” Geoderma 77 (2-4):169–95.
Kempen, B., D.J. Brus, G.B.M. Heuvelink, and J.J. Stoorvogel. 2009. “Updating the 1:50,000 Dutch soil map using legacy soil data: A multinomial logistic regression approach.” Geoderma 151 (3-4):311–26. https://doi.org/10.1016/j.geoderma.2009.04.023.
Wösten, J.H.M., Y.A. Pachepsky, and W.J. Rawls. 2001. “Pedotransfer functions: Bridging the gap between available basic soil data and missing soil hydraulic functions.” Journal of Hydrology 251:123–50.
Wösten, J.H.M., S.J.E. Verzandvoort, J.G.B. Leenaars, T. Hoogland, and J.G. Wesseling. 2013. “Soil Hydraulic Information for River Basin Studies in Semi-Arid Regions.” Geoderma 195. Elsevier:79–86. https://doi.org/10.1016/j.geoderma.2012.11.021.
Dobos, E., F. Carré, T. Hengl, H. I. Reuter, and G. Tóth. 2006. Digital Soil Mapping: As a Support to Production of Functional Maps. Luxemburg: Office for Official Publications of the European Communities.
Burrough, P. A., and R. A. McDonnell. 1998. Principles of Geographical Information Systems. 2nd ed. Oxford: Oxford University Press.
Avery, B. 1987. Soil Survey Methods: A Review. Technical Monograph No. 18. Silsoe: Soil Survey & Land Resource Centre.
Legros, J.-P. 2006. Mapping of the Soil. 1st ed. Enfield, New Hampshire: Science Publishers.
Miller, F. P., D. E. McCormack, and J. R. Talbot. 1979. “The Mechanics of Track Support, Piles and Geotechnical Data.” In, 57–65. Symposium, Trans. Res. Record 733. Washington D.C.: Board. Natl. Acad. Sci.
Hudson, B. D. 2004. “The soil survey as a paradigm-based science.” Soil Science Society of America Journal 56:836–41.
Jenny, H. 1994. Factors of Soil Formation: A System of Quantitative Pedology. Dover Books on Earth Sciences. Dover Publications.
Hengl, T., G.B.M. Heuvelink, and D.G. Rossiter. 2007. “About Regression-Kriging: From Equations to Case Studies.” Computers & Geosciences 33 (10). Elsevier:1301–15.
MacMillan, R. A., W. W. Pettapiece, and J. A. Brierley. 2005. “An Expert System for Allocating Soils to Landforms Through the Application of Soil Survey Tacit Knowledge.” Canadian Journal of Soil Science, 103–12.
Soil Survey Staff. 1983. Soil Survey Manual. Rev. Vol. Handbook 18. Washington: United States Agriculture, USDA.
Rossiter, D.G. 2003. Methodology for Soil Resource Inventories. 3rd ed. ITC Lecture Notes Sol.27. Enschede, the Netherlands: ITC.
Zhu, A.X., B. Hudson, J. Burt, K. Lubich, and D. Simonson. 2001. “Soil Mapping Using Gis, Expert Knowledge, and Fuzzy Logic.” Soil Science Society of America Journal 65:1463–72.
Marsman, B.A., and J.J. de Gruijter. 1986. Quality of Soil Maps: A Comparison of Soil Survey Methods in a Sandyarea. Vol. 15. Soil Survey Papers. Wageningen: Netherlands Soil Survey Institute.
Finke, P. 2006. “Quality assessment of digital soil maps: producers and users perspectives.” In Digital Soil Mapping: An Introductory Perspective, edited by P. Lagacherie, A. B. McBratney, and M. Voltz, 523–41. Developments in Soil Science. Amsterdam: Elsevier.
MacMillan, R.A., D.E. Moon, R.A. Coupé, and N. Phillips. 2010. “Predictive Ecosystem Mapping (Pem) for 8.2 Million Ha of Forestland,British Columbia, Canada.” In Digital Soil Mapping: Bridging Research, Environmental Application, and Operation, edited by J.L. Boettinger et al., 2:335–54. Progress in Soil Science. Springer. https://doi.org/10.1007/978-90-481-8863-5_27.
Rosenbaum, U., H. R. Bogena, M. Herbst, J. A. Huisman, T. J. Peterson, A. Weuthen, A. W. Western, and H. Vereecken. 2012. “Seasonal and Event Dynamics of Spatial Soil Moisture Patterns at the Small Catchment Scale.” Water Resources Research 48 (10):1–22. https://doi.org/10.1029/2011WR011518.
Gasch, Caley, Tomislav Hengl, Benedikt Gräler, Hanna Meyer, Troy Magney, and David Brown. 2015. “Spatio-temporal interpolation of soil water, temperature, and electrical conductivity in 3D+T: The Cook Agronomy Farm data set.” Spatial Statistics 14 (Part A):70–90. https://doi.org/10.1016/j.spasta.2015.04.001.
Hengl, Tomislav, Gerard B.M. Heuvelink, Bas Kempen, Johan G.B. Leenaars, Markus G. Walsh, Keith D. Shepherd, Andrew Sila, et al. 2015. “Mapping Soil Properties of Africa at 250 m Resolution: Random Forests Significantly Improve Current Predictions.” PLoS ONE 10 (e0125814). Public Library of Science. https://doi.org/10.1371/journal.pone.0125814.
Grunwald, S. 2005a. Environmental Soil-Landscape Modeling: Geographic Information Technologies and Pedometrics. Books in Soils, Plants, and the Environment Series. Taylor & Francis.
Lagacherie, P., A. B. McBratney, and M. Voltz, eds. 2006. Digital Soil Mapping: An Introductory Perspective. Developments in Soil Science. Amsterdam: Elsevier.
Hartemink, Alfred E., Alex McBratney, and Maria de Lourdes Mendonça-Santos, eds. 2008. Digital Soil Mapping with Limited Data. Vol. 1. Progress in Soil Science. Springer.
Boettinger, J. L., D. W. Howell, A. C. Moore, A. E. Hartemink, and S. Kienast-Brown, eds. 2010. Digital Soil Mapping: Bridging Research, Environmental Application, and Operation. Vol. 2. Progress in Soil Science. Springer.
Franklin, J. 1995. “Predictive Vegetation Mapping: Geographic Modelling of Biospatial Patterns in Relation to Environmental Gradients.” Progress in Physical Geography 19 (4):474–99.
Hengl, T., M.G. Walsh, J. Sanderman, I. Wheeler, S.P. Harrison, and I.C. Prentice. 2018. “Global Mapping of Potential Natural Vegetation: An Assessment of Machine Learning Algorithms for Estimating Land Potential.” PeerJ 6 (August):e5457. https://doi.org/10.7717/peerj.5457.
Malone, B.P., B. Minasny, and A.B. McBratney. 2016. Using R for Digital Soil Mapping. Progress in Soil Science. Springer International Publishing.
McBratney, A.B., B. Minasny, and U. Stockmann. 2018. Pedometrics. Progress in Soil Science. Springer International Publishing.
Zhong, B., and Y.J. Xu. 2011. “Scale Effects of Geographical Soil Datasets on Soil Carbon Estimation in Louisiana, Usa: A Comparison of Statsgo and Ssurgo.” Pedosphere 21 (4):491–501. https://doi.org/10.1016/S1002-0160(11)60151-3.
Henderson, B. L., E. N. Bui, C. J. Moran, and D. A. P. Simon. 2004. “Australia-wide predictions of soil properties using decision trees.” Geoderma 124 (3-4):383–98.
Mansuy, Nicolas, Evelyne Thiffault, David Pare, Pierre Bernier, Luc Guindon, Philippe Villemaire, Vincent Poirier, and Andre Beaudoin. 2014. “Digital Mapping of Soil Properties in Canadian Managed Forests at 250 M of Resolution Using the K-Nearest Neighbor Method.” Geoderma 235-236 (0):59–73. https://doi.org/10.1016/j.geoderma.2014.06.032.
Rowe, J. Stan, and John W. Sheard. 1981. “Ecological Land Classification: A Survey Approach.” Environmental Management 5 (5). Springer:451–64.
Gibbons, Frank R., Ronald Geoffrey Downes, and others. 1964. A study of the land in south-western Victoria. Soil Conservation Authority Melbourne.
Rowan, James Niall. 1990. Land Systems of Victoria. Land Protection Division.
Ramcharan, Amanda, Tomislav Hengl, Travis Nauman, Colby Brungard, Sharon Waltman, Skye Wills, and James Thompson. 2018. “Soil Property and Class Maps of the Conterminous United States at 100-Meter Spatial Resolution.” Soil Science Society of America Journal 82. The Soil Science Society of America, Inc.:186–201. https://doi.org/10.2136/sssaj2017.04.0122.
Arrouays, Dominique, Johan GB Leenaars, Anne C Richer-de-Forges, Kabindra Adhikari, Cristiano Ballabio, Mogens Greve, Mike Grundy, et al. 2017. “Soil legacy data rescue via GlobalSoilMap and other international and national initiatives.” GeoResJ 14. Elsevier:1–19.
Schoeneberger, P.J., D.A. Wysocki, E.C. Benham, and W.D. Broderson. 1998. Field Book for Describing and Sampling Soils. Lincoln, Nebraska: Natural Resources Conservation Service, USDA, National Soil Survey Centre.
Gehl, RonaldJ., and CharlesW. Rice. 2007. “Emerging Technologies for in Situ Measurement of Soil Carbon.” Climatic Change 80 (1-2). Kluwer Academic Publishers:43–54. https://doi.org/10.1007/s10584-006-9150-2.
Shepherd, K.D., and M.G. Walsh. 2007. “Infrared Spectroscopy — Enabling an Evidence Based Diagnostic Survellance Approach to Agricultural and Environmental Management in Developing Countries.” Journal of Near Infrared Spectroscopy 15:1–19.
Sanchez et al. 2009. “Digital Soil Map of the World.” Science 325:680–81.
Hartemink, A. E., J. Hempel, P. Lagacherie, A. B. McBratney, N. McKenzie, R. A. MacMillan, B. Minasny, et al. 2010. “GlobalSoilMap.net — A New Digital Soil Map of the World.” In Digital Soil Mapping: Bridging Research, Environmental Application, and Operation, edited by J. L. Boettinger, D. W. Howell, A. C. Moore, A. E. Hartemink, and S. Kienast-Brown, 2:423–27. Progress in Soil Science. Springer.
Leenaars, Johan G.B. 2014. Africa Soil Profiles Database, Version 1.2. A Compilation of Geo-Referenced and Standardized Legacy Soil Profile Data for Sub Saharan Africa (with Dataset). Wageningen, the Netherlands: Africa Soil Information Service (AfSIS) project; ISRIC — World Soil Information.
Omuto, C., F. Nachtergaele, and R. Vargas Rojas. 2012. State of the Art Report on Global and Regional Soil Information: Where are we? Where to go? Global Soil Partnership Technical Report. Rome: FAO.
White, R.E. 2009. Principles and Practice of Soil Science: The Soil as a Natural Resource. Wiley.
McBratney, A. B., B. Minasny, R. A. MacMillan, and F. Carré. 2011. “Digital Soil Mapping.” In Handbook of Soil Science, edited by H. Li and M.E. Sumner, 37:1–45. CRC Press.
Simonson, Roy W. 1968. “Concept of Soil.” In Prepared Under the Auspices of the American Society of Agronomy, edited by A.G. Norman, 20:1–47. Advances in Agronomy. Academic Press. https://doi.org/10.1016/S0065-2113(08)60853-6.
Hartemink, Alfred. 2008. “Soil Map Density and a Nation’s Wealth and Income.” In Digital Soil Mapping with Limited Data, edited by Alfred Hartemink, Alex McBratney, and Mariade Lourdes Mendonça-Santos, 53–66. Springer Netherlands. https://doi.org/10.1007/978-1-4020-8592-5_1.
Heuvelink, G.B.M., and R. Webster. 2001. “Modelling soil variation: past, present, and future.” Geoderma 100 (3-4).
Rossiter, D.G. 2003. Methodology for Soil Resource Inventories. 3rd ed. ITC Lecture Notes Sol.27. Enschede, the Netherlands: ITC.
2004. “Digital Soil Resource Inventories: Status and Prospects.”
Soil Use and Management 20 (3). Blackwell Publishing Ltd:296–301.
https://doi.org/10.1111/j.1475-2743.2004.tb00372.x.
Lathrop Jr., Richard G., John D. Aber, and John A. Bognar. 1995. “Spatial Variability of Digital Soil Maps and Its Impact on Regional Ecosystem Modeling.” Ecological Modelling 82 (1):1–10. https://doi.org/10.1016/0304-3800(94)00068-S.
Grinand, C., D. Arrouays, B. Laroche, and M. Martin. 2008. “Extrapolating regional soil landscapes from an existing soil map: Sampling intensity, validation procedures, and integration of spatialcontext.” Geoderma 143:180–90. https://doi.org/10.1016/j.geoderma.2007.11.004.
Hengl, Tomislav, and Stjepan Husnjak. 2006. “Evaluating Adequacy and Usability of Soil Maps in Croatia.” Soil Science Society of America Journal 70 (3):920–29. https://doi.org/10.2136/sssaj2004.0141.
D’Avello, T.P., and R.L. McLeese. 1998. “Why Are Those Lines Placed Where They Are? An Investigation of Soil Map Recompilation Methods.” Soil Survey Horiz. 39:119–26.
McBratney, Alex, Nathan Odgers, and Budiman Minasny. 2006. “Random Catena Sampling for Establishing Soil-Landscape Rules forDigital Soil Mapping.” In 18th World Congress of Soil Science, 4. Philadelphia, Pennsylvania: IUSS.
Walter, C., P. Lagacherie, and S. Follain. 2006. “Integrating Pedological Knowledge into Digital Soil Mapping.” In Digital Soil Mapping — an Introductory Perspective, edited by P. Lagacherie, A. B. McBratney, and M. Voltz, 31:281–300, 615. Developments in Soil Science. Elsevier. https://doi.org/10.1016/S0166-2481(06)31022-7.
Christakos, G., P. Bogaert, and M.L. Serre. 2001. Temporal GIS: advanced functions for field-based applications. v. 1. Springer.
Zhou, Bin, Xin-gang Zhang, and Ren-chao Wang. 2004. “Automated Soil Resources Mapping Based on Decision Tree and Bayesian Predictive Modeling.” Journal of Zhejiang University Science 5:782–95. https://doi.org/10.1631/jzus.2004.0782.
Hengl, T., J. Mendes de Jesus, G. B. M. Heuvelink, M. Ruiperez Gonzalez, M. Kilibarda, A. Blagotic, W. Shangguan, et al. 2017. “SoilGrids250m: Global Gridded Soil Information Based on Machine Learning.” PLoS One 12 (2):e0169748.
Lei, Simon A. 1998. “Soil Properties of the Kelso Sand Dunes in the Mojave Desert.” The Southwestern Naturalist 43 (1). Southwestern Association of Naturalists:47–52.
Raup, Bruce, Adina Racoviteanu, Siri Jodha Singh Khalsa, Christopher Helm, Richard Armstrong, and Yves Arnaud. 2007. “The GLIMS geospatial glacier database: a new tool for studying glacier change.” Global and Planetary Change 56 (1). Elsevier:101–10.
Beaudette, D., and A.T. O’Geen. 2009. “Soil-web: An online soil survey for California, Arizona, and Nevada.” Computers & Geosciences 35:2119–28.
Campbell, Andrew. 2008. Managing Australia’s Soils: A policy discussion paper. Canberra: CSIRO.
Goodchild, M.F. 2008. “Spatial Accuracy 2.0.” In Proceedings of the 8th International Symposium on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences, edited by Wan, Y. et al., 1–7. World Academic Union (Press).
O’Geen, Anthony, Mike Walkinshaw, and Dylan Beaudette. 2017. “SoilWeb: A Multifaceted Interface to Soil Survey Information.” Soil Science Society of America Journal 81 (4). The Soil Science Society of America, Inc.:853–62.
Harpstead, M.I., T.J. Sauer, and W.F. Bennett. 2001. Soil Science Simplified. Wiley.
Walker, W.E., P. Harremoës, J. Rotmans, J.P. van der Sluijs, M.B.A. van Asselt, P. Janssen, and M.P.K von Krauss. 2003. “Defining Uncertainty: A Conceptual Basis for Uncertainty Management in Model-Based Decision Support.” Integrated Assessment 4 (1):5–17.
Refsgaard, Jens Christian, Jeroen P. van der Sluijs, Anker Lajer Højberg, and Peter A. Vanrolleghem. 2007. “Uncertainty in the environmental modelling process — A framework and guidance.” Environ. Model. Softw. 22 (11):1543–56. https://doi.org/10.1016/j.envsoft.2007.02.004.
Heuvelink, G.B.M., and J. Brown. 2006. “Towards a Soil Information System for Uncertain Soil Data.” In Digital Soil Mapping: An Introductory Perspective, edited by P. Lagacherie, A. B. McBratney, and M. Voltz, 112–18. Developments in Soil Science. Amsterdam: Elsevier.
Panagos, Panos, Roland Hiederer, Marc Van Liedekerke, and Francesca Bampa. 2013. “Estimating soil organic carbon in Europe based on data collected through an European network.” Ecological Indicators 24 (0):439–50. https://doi.org/10.1016/j.ecolind.2012.07.020.
Kuhn, Max, and Kjell Johnson. 2013. Applied Predictive Modeling. Vol. 810. Springer.
Heuvelink, Gerard BM. 2014. “Uncertainty Quantification of Globalsoilmap Products.” In GlobalSoilMap: Basis of the Global Spatial Soil Information System, edited by D. Arrouays, N. McKenzie, J. Hempel, A.R. de Forges, and A.B. McBratney, 327–32. Taylor & Francis.
Pleijsier, L.K. 1984. Laboratory Methods and Data Quality. Program for Soil Characterization: A Report on the Pilot Round. Part Ii. Exchangeable Bases, Base Saturation and pH. Wageningen: International Soil Reference; Information Centre.
1986.
The Laboratory Methods and Data Exchange Programme. Interim Report on the Exchange Round 85-2. Wageningen: International Soil Reference; Information Centre.
van Reeuwijk, L.R. 1982. “Laboratory Methods and Data Quality. Program for Soil Characterization: A Report on the Pilot Round. Part I. CEC and Texture.” In Proceedings of 5th International Classification Workshop. Khartoum, Sudan: ISRIC.
Pleijsier, L.K. 1984. Laboratory Methods and Data Quality. Program for Soil Characterization: A Report on the Pilot Round. Part Ii. Exchangeable Bases, Base Saturation and pH. Wageningen: International Soil Reference; Information Centre.
Lagacherie, P. 1992. “Formalisation Des Lois de Distribution Des Sols Pour Automatiser La Cartographie Pédologique à Partir d’un Secteur Pris Comme Référence. Cas de La Petite Région ‘Moyenne Vallée de L’Hérault’.” PhD thesis, Montpellier: Université des Sciences et Techniques du Languedoc.
Oreskes, Naomi, Kristin Shrader-Frechette, and Kenneth Belitz. 1994. “Verification, Validation, and Confirmation of Numerical Models in the Earth Sciences.” Science 263 (5147):641–46. https://doi.org/10.1126/science.263.5147.641.